SQL은 DataBase (DB)에서 원하는 데이터를 조회 할 때 주로 사용된다.
SQL (Structured Query Language)이란?
관계형 데이터 베이스 관리 시스템 (RDBMS)의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어이다.
즉 DB에서 데이터를 CRUD를 하기위해 사용하는 언어인 것이다.
- CRUD란
- C (Create) : 데이터의 생성을 의미
- R (Read) : 저장된 데이터를 읽어오는 것을 의미
- U (Update) : 저장된 데이터를 변경
- D (Delete) : 저장된 데이터를 삭제하는 것을 의미
실무에서 SQL은 사용자에 따라서 자주 사용하는 문법이 다르다.
DB 설계자의 경우 C,U,D를 많이 사용할 것이고
데이터 분석가의 경우 R을 제일 많이 사용할 것이다.
SQL은 데이터를 정의하고 (Data Definition), 조작하며 (Data Manipulation, 조작한 결과를 적용하거나 취소할 수 있고 (Transaction Control), 접근 권한을 제어하는 (Data Control) 처리들로 구성됨
이 글에서는 데이터 분석가의 관점에서 데이터를 조회하는 SQL 사용 예시에 대해서 기록하려고 한다.
SQL 쿼리 문법
- 쿼리문이란? DB에 내리는 명령
- Select : 데이터 조회
- Where : Select 쿼리문으로 가져올 데이터에 조건을 설정 할 수있음
- Group by : 동일한 범주를 갖는 데이터를 하나로 묶을 수 있음
- Order by :
- Join : 특정 필드를 기준으로 여러 테이블 합치기
- Limit : 일부 데이터만 가져오기
- Distinct : 중복 데이터는 제외하고 가져오기
- Count : 데이터 개수 세기
- Union : 결과물 합치기
- with : 갈수록 길어지는 서브쿼리를 줄이기 위한 방법
- Substring : 문자열 자르기
- Case When ~ Else end : 조건문
- 서브쿼리 (Subquery) : 하나의 SQL 쿼리 안에 또 다른 SQL 쿼리가 있는 것을 의미
- Join 종류
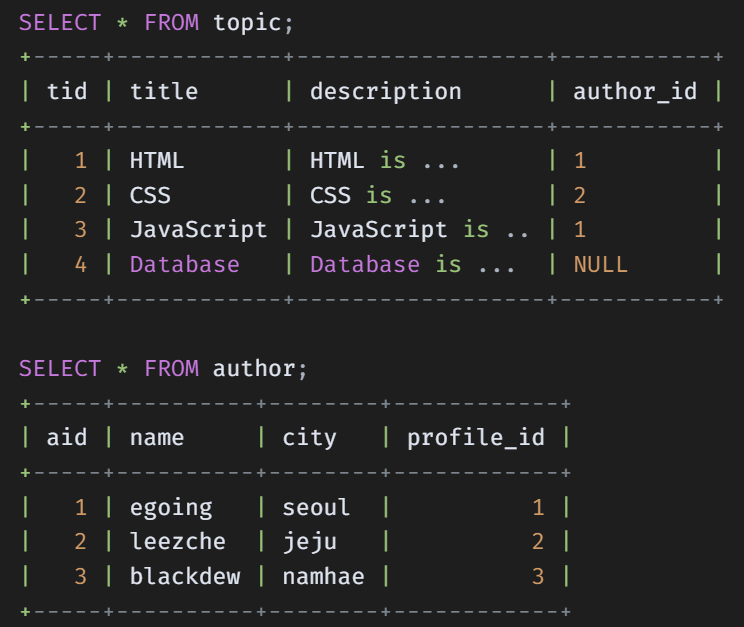
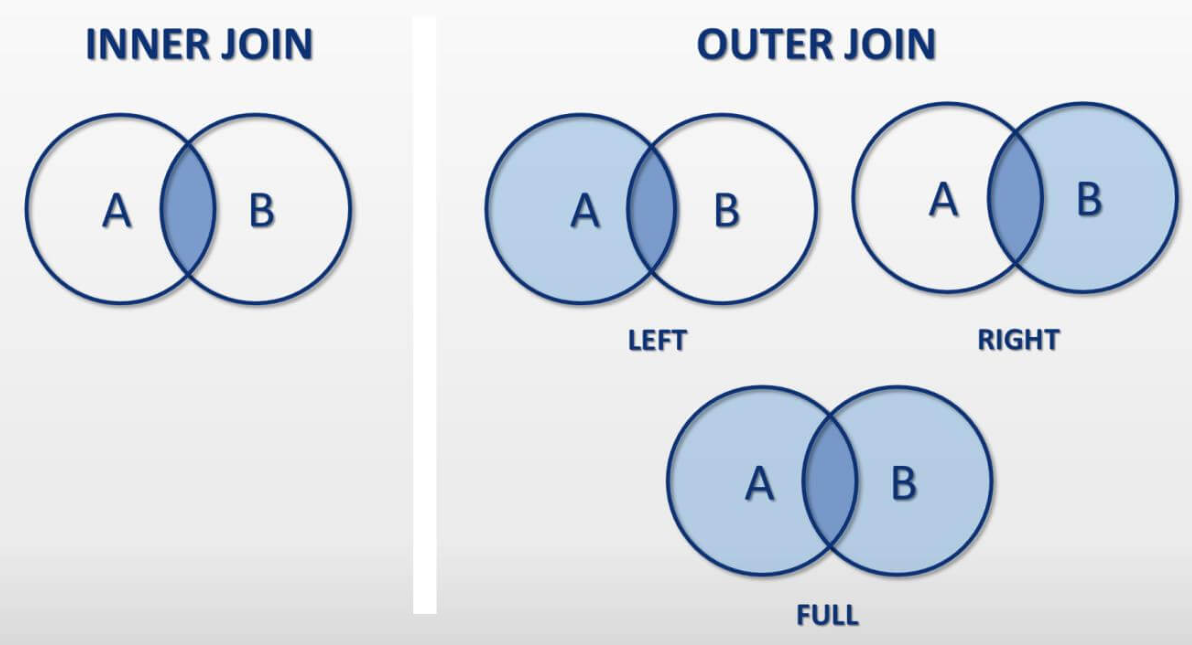
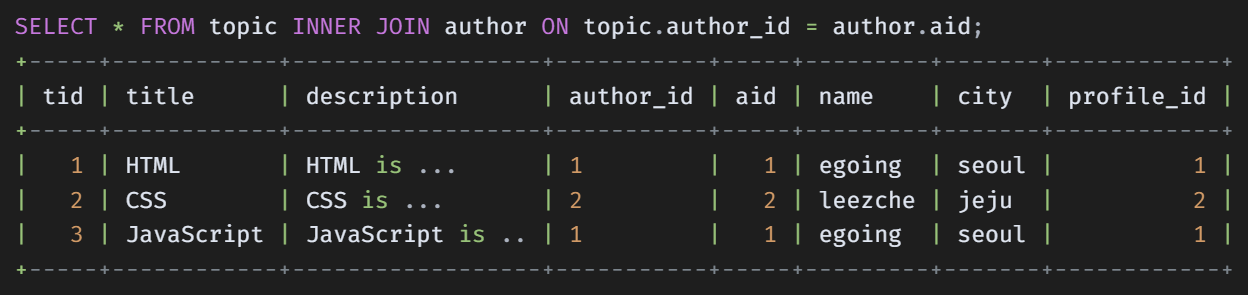
1. Inner Join (교집합)
2. Left Join (왼쪽 테이블 기준 합집합)
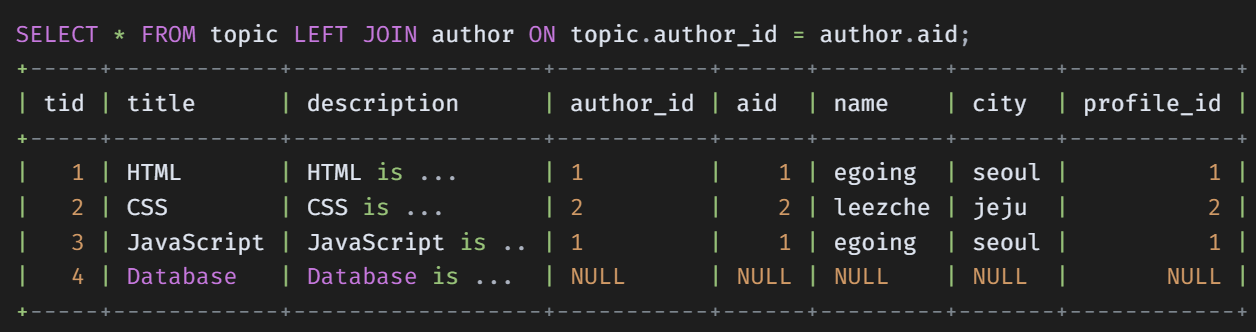
결과가 같다면 Left Join 대신 Inner Join을 사용하는 것이 속도 측면에서 유리
Inner Join의 경우 교집합에 대해서 조회하므로 조회 속도가 상대적으로 빠르기 때문
Left join은 한쪽에는 없지만 한쪽에는 있는 필드에 대한 통계량을 내고 싶을 때 사용함
SQL 사용 예시
- SQL 쿼리 실행 순서
select u.name, count(u.name) as count_name from orders o
inner join users u
on o.user_id = u.user_id
where u.email like '%naver.com'
group by u.name- from orders o: orders 테이블 데이터 전체를 가져오고 o라는 별칭을 붙입니다.
- inner join users u on o.user_id = u.user_id : users 테이블을 orders 테이블에 붙이는데, orders 테이블의 user_id와 동일한 user_id를 갖는 users 테이블 데이터를 붙입니다. (*users 테이블에 u라는 별칭을 붙입니다)
- where u.email like '%naver.com': users 테이블 email 필드값이 naver.com으로 끝나는 값만 가져옵니다.
- group by u.name: users 테이블의 name값이 같은 값들을 뭉쳐줍니다.
- select u.name, count(u.name) as count_name : users 테이블의 name필드와 name 필드를 기준으로 뭉쳐진 갯수를 세어서 출력해줍니다.
Join의 실행 순서는 항상 from과 붙어다닌다고 생각하자!
Q1. 웹개발, 앱개발 종합반의 week 별 체크인 수 중에서 8월 1일 이후에 구매한 고객의 수는?
select c1.title, c2.week, count(*) as cnt from courses c1
inner join checkins c2 on c1.course_id = c2.course_id
inner join orders o on c2.user_id = o.user_id
where o.created_at >= '2020-08-01'
group by c1.title, c2.week
order by c1.title, c2.week
Q2. 유저 중에, 포인트가 없는 사람의 통계
Left join은 한쪽에는 없지만 한쪽에는 있는 필드에 대한 통계량을 내고 싶을 때 사용함 → is not Null 사용
select name, count(*) from users u
left join point_users pu on u.user_id = pu.user_id
where pu.point_user_id is NULL
group by name
select name, count(*) from users u
left join point_users pu on u.user_id = pu.user_id
where pu.point_user_id is not NULL
group by name
Q3. 7월10일 ~ 7월19일에 가입한 고객 중, 포인트를 가진 고객의 숫자, 그리고 전체 숫자, 그리고 비율은?
select count(point_user_id) as pnt_user_cnt,
count(*) as tot_user_cnt,
round(count(point_user_id)/count(*),2) as ratio
from users u
left join point_users pu on u.user_id = pu.user_id
where u.created_at between '2020-07-10' and '2020-07-20'
서브쿼리 예시
Q4. 이씨 성을 가진 유저의 포인트의 평균보다 큰 유저들의 데이터 추출하기
→ 평균이 계속 바뀌는 상황이라면 서브쿼리로 평균을 표현하면 편리하다
#1번 정답
select * from point_users pu
where pu.point >
(select avg(pu2.point) from point_users pu2
inner join users u on pu2.user_id = u.user_id
where u.name = "이**");
#2번 정답 : Subquery 안에 또 Subquery
select * from point_users pu
where point >
(select avg(point) from point_users pu
where user_id in (
select user_id from users where name= "이**"
)
)Q5. checkins 테이블에 과목명별 평균 likes수 필드 우측에 붙여보기
select checkin_id, c3.title, user_id, likes,
(select round(avg(c2.likes),1) from checkins c2
where c.course_id = c2.course_id) as course_avg
from checkins c
inner join courses c3 on c.course_id = c3.course_id;
Q6. course_id별 like 개수에 전체 인원을 붙이기
select a.course_id, b.cnt_checkins, a.cnt_total from
(
select course_id, count(*) as cnt_total from orders
group by course_id
) a
inner join (
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
) b
on a.course_id = b.course_id
문자열 관련 예시
Q7. [문자열 쪼개기] 이메일에서 이메일 도메인만 가져와보기
select user_id, email, SUBSTRING_INDEX(email, '@', -1) from usersQ8. [문자열 일부 출력] 일별로 몇 개씩 주문이 일어났는지 살펴보기
select substring(created_at,1,10) as date, count(*) as cnt_date from orders
group by date
Q9. [CASE] 경우에 따라 원하는 값을 새 필드에 출력해보기
→ 조건문을 넣을 때 Case When ~ else End 구문 사용
select pu.point_user_id, pu.point,
case when pu.point > 10000 then '잘 하고 있어요!'
else '조금 더 달려주세요!' END as '구분'
from point_users pu;Q10. 평균 이상 포인트를 가지고 있으면 '잘 하고 있어요' / 낮으면 '열심히 합시다!' 표시하기!
select pu.point_user_id, pu.point,
case when pu.point > (select avg(pu2.point) from point_users pu2) then '잘 하고 있어요!'
else '열심히 합시다!' end as 'msg'
from point_users puQ11. 수강등록정보(enrolled_id)별 전체 강의 수와 들은 강의의 수 출력해보기
(done_cnt는 들은 강의의 수(done=1), total_cnt는 전체 강의의 수)
with lecture_done as (
select enrolled_id, count(*) as cnt_done from enrolleds_detail ed
where done = 1
group by enrolled_id
), lecture_total as (
select enrolled_id, count(*) as cnt_total from enrolleds_detail ed
group by enrolled_id
)
select a.enrolled_id, a.cnt_done, b.cnt_total from lecture_done a
inner join lecture_total b on a.enrolled_id = b.enrolled_id
Q12. 수강등록정보(enrolled_id)별 전체 강의 수와 들은 강의의 수, 그리고 진도율 출력해보기
with table1 as (
select enrolled_id, count(*) as done_cnt from enrolleds_detail
where done = 1
group by enrolled_id
), table2 as (
select enrolled_id, count(*) as total_cnt from enrolleds_detail
group by enrolled_id
)
select a.enrolled_id,
a.done_cnt,
b.total_cnt,
round(a.done_cnt/b.total_cnt,2) as ratio
from table1 a
inner join table2 b on a.enrolled_id = b.enrolled_id
Q13. 그러나, Q12를 더 간단하게 만들 수 있지 않을까!
select enrolled_id,
sum(done) as cnt_done,
count(*) as cnt_total
from enrolleds_detail ed
group by enrolled_id
'SQL' 카테고리의 다른 글
| SQL 집계 함수 (Aggregate Function)와 윈도우 함수 (Window Function) (0) | 2024.03.27 |
|---|---|
| 서브쿼리, 집합 연산자, window 함수 (0) | 2024.03.27 |
| SQL 파싱 부하 (0) | 2023.03.21 |
| SQL 쿼리문 튜닝 - 효율적인 SQL 작성법 (0) | 2023.03.21 |

