SQL 공부하다 보니 2개의 유형의 그룹핑과 관련 함수에 대해 각각의 역할이 헷갈려 정리함
집계 함수(aggregate functions) 와 윈도우 함수(window functions)
집계 함수 (Aggregate Function)
집계함수는 여러 행의 결과를 단 1개의 결과로 반환함, 그리고 Group by와 대부분 함께 사용함
왜냐면 어떤 기준을 통해 묶인 집계된 그룹이 있어야, 그 그룹에 집계 함수를 적용할 수 있기 때문
집계함수는 where 절 다음에 진행이 되기 때문에 where 절에 못씀
하지만 서브 쿼리 안에 쓰는 경우에는 사용 할 수 있음
- AVG() : 여러 행의 수치의 평균 값을 반환
- SUM() : 여러 행의 수치의 총 합을 반환
- MAX()와 MIN() : 여러 행의 수치 내에서 각각 최댓값과 최솟값을 반환
- COUNT() : 여러 행의 수치의 총개수를 반환
- 등...
주로 Group By 구문과 함께 사용
예시) 아래 테이블을 기반으로 집계함수를 사용하여 각 도시별 일별 평균 거래액을 계산

집계함수 AVG() 를 활용해서 날짜와 도시를 기준으로 Group by 하면
SELECT
date,
city,
AVG(amount) AS avg_transaction_amount_for_cities
FROM transactions
GROUP BY date, city;
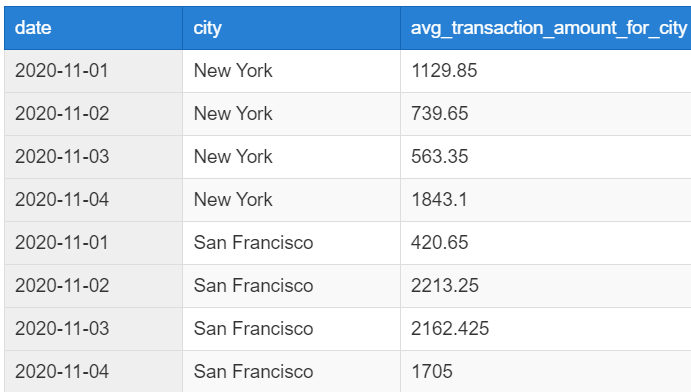
원래 테이블 10 행
집계함수 + group by 한 결과는 총 8행, 그리고 조회할 수 있는 컬럼들에 제약이 있음
→ 조회를 하면서 데이터가 줄어들었다.
즉 집계 함수는 여러 개의 행들을 합쳐 1개의 값을 반환한다.
윈도우 함수 (Window Function)
윈도우 함수는 각 행마다 1개의 값을 반환
Over() 구문을 필수적으로 사용하여 무엇으로 구분 짓느냐에 따라 하나의 열 안에 있는 여러 행들을 여러 차응로 나눔
마치 Group by처럼
SELECT
id,
date,
city,
amount,
AVG(amount) OVER(PARTITION BY date, city) AS avg_daily
FROM transactions
ORDER BY id;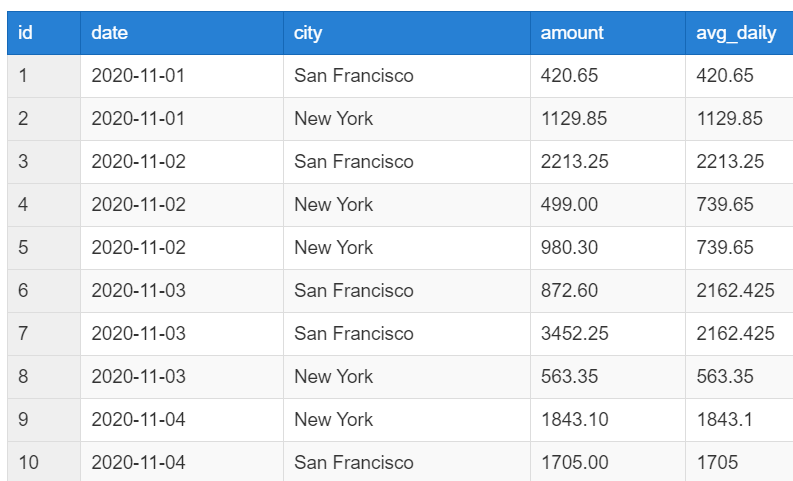
원래 테이블의 데이터 행은 10개
윈도우 함수를 실행한 데이터의 행 10개
→ 행 데이터 개수 변화 없음, 조회할 수 있는 컬럼도 제약이 없고, 윈도우 함수를 통해 계산하고자 했던 결과를 따로 컬럼을 만들어서 볼 수 있음
공통점과 차이점
윈도우 함수와 집계 함수 모두
1. 여러 행의 수치를 가지고 계산합니다.
2. 여러 행 내의 값을 집계된 값으로 계산할 수 있습니다 (평균값, 합, 최댓값, 최솟값, 개수 등)
3. 1개 또는 1개 이상의 열을 기준으로 데이터를 그룹핑할 수 있습니다.
GROUP BY와 함께 쓰인 집계 함수 관점에서의 차이점
1. 그룹핑을 할 행의 범위를 정할 때 GROUP BY를 사용합니다.
2. 특정 열 내의 값을 가지고 행을 합칩니다.
3. GROUP BY에서 명시된 열로만 행을 합칠 수 있습니다.
윈도우 함수 관점에서의 차이점
1. 그룹핑을 할 행의 범위를 정할 때 OVER()을 사용합니다.
2. 집계 함수 이외에도 다른 함수와 함께 사용할 수 있습니다 (e.g. RANK(), LAG(), LEAD() 등)
3. 특정 열 내의 값 이외에도 행의 순위, 퍼센타일 등을 가지고도 행을 합칠 수 있습니다.
4. 기존의 행에 변화를 주지 않습니다.
5. 현재 행과 연관 있는 구간만 따로 설정해 계산할 수 있습니다 (영어로는 sliding window frame라는 용어를 사용함)
이번에는 날짜별로 당일과 그 전날의 평균 거래액을 계산하고 싶습니다(i.e. 11월 2일이라면 당일인 11월 2일과 전날인 11월 1일의 평균 거래액). 우선 날짜별 거래액을 구하기 위해서 Common Table Expression (CTE)를 사용해 daily_sales란 테이블을 임시로 생성하고자 합니다. 그런 후, 윈도우 함수와 더불어 sliding window frame을 활용해 당일과 연관된 전날이라는 구간을 설정한 후 두 날짜의 거래액의 평균을 계산할 겁니다. 쿼리는 아래와 같습니다.
WITH daily_sales AS (
SELECT
date,
SUM(amount) AS sales_per_day,
FROM transactions
GROUP BY date)
SELECT
date,
AVG(sales_per_day) OVER(ORDER BY date ROWS 1 PRECEDING) AS avg_2days_sales
FROM daily_sales
ORDER BY date;
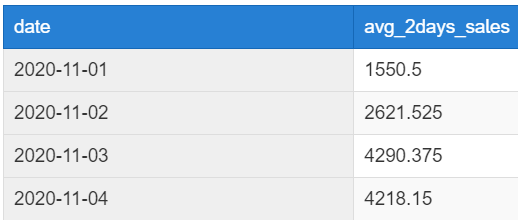
첫 번째 행인 11월 1일은 테이블 내에 전날인 10월 31일 데이터가 존재하지 않기 때문에 11월 1일의 거래액이 반환됐네요. 두 번째 행인 11월 2일부터는 전날이 존재하므로 11월 1일과 11월 2일의 평균 거래액이 계산되어 반환됐고, 3번째 행은 11월 2일과 11월 3일의 평균 거래액이 계산되어 반환됐습니다.
이와 같이 윈도우 함수는 현재 행을 기준으로 이와 연관된 구간을 설정하여 집계 값을 구할 때 상당히 용이합니다. 이건 단순히 집계 함수와 GROUP BY로는 구할 수 없거든요.
https://learnsql.com/blog/window-functions-vs-aggregate-functions/
Aggregate Functions vs Window Functions: A Comparison
Explore the contrast of window functions vs. SQL aggregate functions: Discover when to apply each for efficient and insightful database operations.
learnsql.com
'SQL' 카테고리의 다른 글
| 서브쿼리, 집합 연산자, window 함수 (0) | 2024.03.27 |
|---|---|
| SQL 파싱 부하 (0) | 2023.03.21 |
| SQL과 사용 예시 (0) | 2023.03.21 |
| SQL 쿼리문 튜닝 - 효율적인 SQL 작성법 (0) | 2023.03.21 |

